感谢支持!您的打赏是我继续创作的动力!


在 DAX 中,筛选函数(Filter functions)是一族可以修改或生成符合特定条件的表格的函数。它们对于控制计算中的 Filter context 至关重要,尤其是在构建复杂的度量值时,筛选函数可以操作数据的 Context,以创建动态计算的度量值。
筛选函数大概可以分为两种:
- 表格筛选函数。这些函数根据指定条件返回已经经过筛选的表,例如 FILTER 函数,它接收一个表表达式1和 Boolean 表达式,返回只包含满足条件的行的新表;
- Filter context 修改器。这些函数可调整应用于计算的 Filter context。它们不仅可以返回已过滤的表格,还可用于移除或修改筛选器。例如 ALL 函数可以删除指定列或表中的所有筛选器。
筛选函数通常被使用在以下场景:
- 动态分析。通过使用筛选函数,可以在报表中创建动态响应的度量值;
- 高级计算。筛选函数可以控制在 Context 中应该包含哪些数据,从而实现复杂的计算;
- 与 CALCULATE 函数配合使用。CALCULATE 函数是 DAX 中最重要的函数之一,因为它可以更改 Filter context。在下文中可以看到在 CALCULATE 中使用筛选函数作为参数,以重新定义计算应考虑哪些行。
总之,筛选函数提供了处理复杂筛选条件所需的灵活性。掌握这些函数就可以控制度量值的 Context,从而实现高级分析功能和更灵活的报表,无论是使用它们来覆盖现有的筛选条件、添加新的条件,还是遍历表中的行。
ALL 系列函数
ALL 函数
ALL 函数能够忽略任何可能已应用的筛选器,并返回所有行或列中的所有值。ALL 函数的最佳实践是用于清除筛选器并对表中的所有行创建计算。
ALL 函数的语法如下:
1
ALL( [<table> | <column>[, <column>[, <column>[,…]]]] )
其中参数 table 表示想要清除筛选器的表,column 表示想要清除筛选器的列,ALL 函数的返回值为已删除筛选器的表或列。
ALL 函数不能与表表达式或者列表达式2一起使用!
示例 1:计算不同商品成本占总成本的比例
假设需求为“计算当前单元格的销售成本除以所有咖啡种类的总销售成本”,为了确保无论数据透视表如何过滤或分组数据分母都是相同的,则可以使用下面的计算式:
1
成本占比 = DIVIDE ( SUMX ( '销售表', '销售表'[成本] ), SUMX ( ALL ( '销售表' ), '销售表'[成本] ) )
于是得到结果如下图所示:
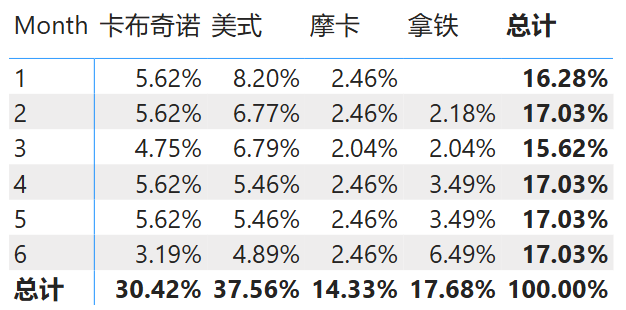
图 1: ALL 函数示例 1 结果
示例 2:计算当月商品成本占总成本的比例
假设需求为“计算每个商品每月的销售额百分比”,那么需要将该特定月份和商品类别的销售总额除以所有月份相同产品类别的销售总额。换句话说要保留商品名称上的筛选器,但在计算百分比的分母时删除月份上的筛选器。则可以使用下面的计算式:
1
2
3
4
5
销售成本占比 =
DIVIDE (
SUMX ( '销售表', '销售表'[成本] ),
CALCULATE ( SUM ( '销售表'[成本] ), ALL ( '日期表'[Month] ) )
)
于是得到结果如下图所示:
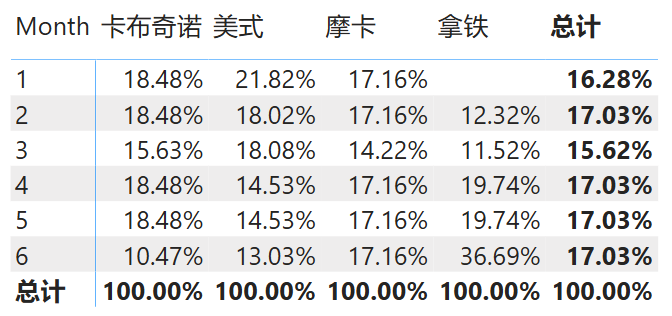
图 2: ALL 函数示例 2 结果
示例 3:计算每月商品成本对该月成本的占比
假设需求为“以每月为基础计算每个商品类别的成本百分比”,那么需要计算该特定商品类别在第 N 月的成本总额,然后将结果值除以第 N 月所有商品类别的成本总额。换句话说在计算百分比的分母时要保留筛选器,但要删除商品名称上的筛选器。则可以使用下面的计算式:
1
2
3
4
5
销售成本占比 =
DIVIDE (
SUMX ( '销售表', '销售表'[成本] ),
CALCULATE ( SUM ( '销售表'[成本] ), ALL ( '商品表'[商品名称] ) )
)
于是得到结果如下图所示:
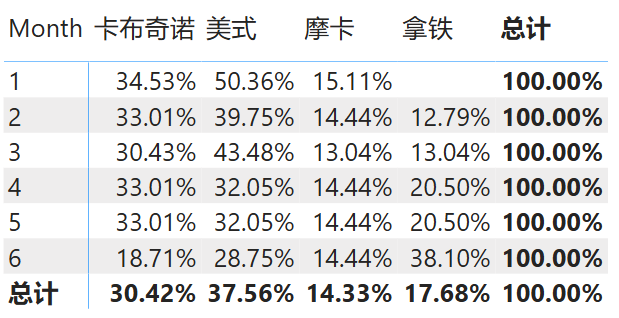
图 3: ALL 函数示例 3 结果
ALLEXCEPT 函数
ALLEXCEPT 函数可以清除应用于指定列外的 Filter context,该函数的语法如下:
1
ALLEXCEPT( <table>, <column>[, <column>[,…]] )
其中参数 table 表示需要删除所有 Context 过滤条件的表,column 表示必须为其保留 Context 的筛选条件的列,ALLEXCEPT 函数的返回值为被保留的列而组成的新表。
当有很多组列名是,使用 ALLEXCEPT 函数可以极大地精简代码长度。
ALLNOBLANKROW 函数
ALLNOBLANKROW 函数被用于删除表中由于某些筛选条件而导致的空白行,以便更准确地进行计算和分析。其语法如下:
1
ALLNOBLANKROW( {<table> | <column>[, <column>[, <column>[,…]]]} )
其中参数 table 表示需要删除所有 Context 筛选条件的表,column 表示需要删除所有 Context 筛选条件的列。当传递的参数是一个表时,该函数的返回值是一个表;当传递的参数是一个列时,返回值则是一个值列。
ALLNOBLANKROW 函数与 ALL 类似,但它会进一步去除所有值为空的行,是数据清理和聚合的有力工具。
ALLSELECTED 函数
ALLSELECTED 函数能够从当前查询中的列和行中删除 Filter Context,同时保留所有其他 Filter Context 或者 Power View 中的筛选条件。ALLSELECTED 函数的语法如下:
1
ALLSELECTED( [<tableName> | <columnName>[, <columnName>[, <columnName>[,…]]]] )
其中参数 tableName 是基础表的名称,columnName 是基础字段的名称,ALLSELECTED 函数的返回值为没有任何列和行筛选器的 Context。
ALLSELECTED 函数如果有多个参数,则它们必须是来自同一张表的列。
ALLSELECTED 函数与 ALL 不同,因为它保留查询中明确设置的所有筛选器,并且保留除行和列筛选器之外的所有 Filter Context。
将 ALL 函数示例 2 的 DAX 表达式中的 ALL 替换成 ALLSELECTED,然后只筛选 1 至 5 月,就可以很明显地看出区别:
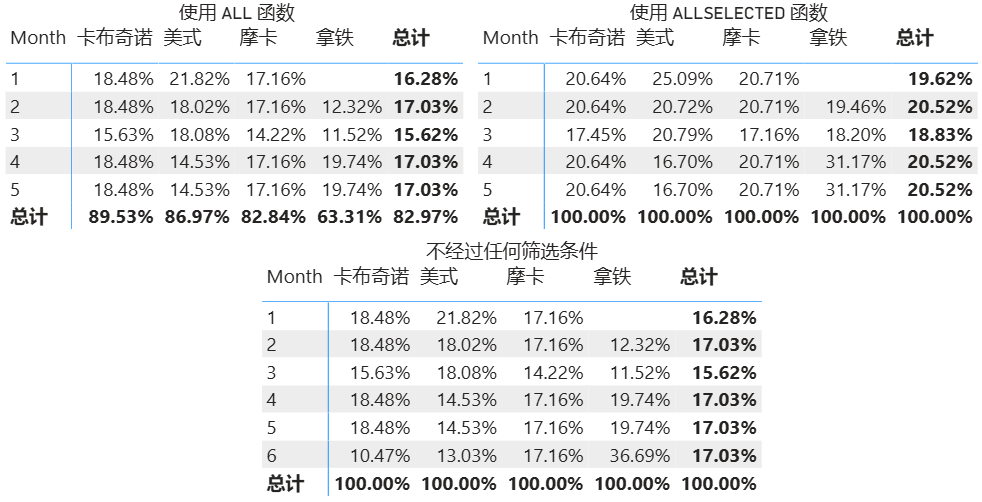
图 4: ALL 函数和 ALLSELECTED 函数的对比
图 4 左边的透视表使用了 ALL 函数,右边的透视表则使用了 ALLSELECTED 函数。可以看出左图的占比数据是基于所有月份计算的,而右图的占比数据是基于筛选条件后的月份计算。
ALLCROSSFILTERED 函数
ALLCROSSFILTERED 函数会清除应用于表的所有筛选器。它的语法如下:
1
ALLCROSSFILTERED(<table>)
其中参数table表示想要清除筛选器的表。值得一提的是 ALLCROSSFILTERED 函数只能用于清除筛选器,而不能返回表。
CALCULATE 函数
CALCULATE 函数的作用是修改 Filter Context 中的表达式。CALCULATE 函数的语法如下:
1
CALCULATE( <expression>[, <filter1> [, <filter2> [, …]]] )
其中参数 expression 表示需要计算的值的表达式,本质上与度量值相同;filter 可以是 Boolean 表达式、表表达式或者 Filter context 修改器函数:
-
Boolean 表达式是求值为
TRUE或FALSE的表达式,其必须遵守以下几条规则:- 可以引用单个表中的列,但不能引用度量值;
- 不能嵌套使用 CALCULATE 函数(有嵌套需求时可以使用 EARLIER 函数)。
- 不能与扫描或返回表格的函数一起使用,除非这些函数作为参数传递给聚合函数,例如
- 可以包含返回值是标量值的聚合函数,例如
1 2 3 4 5
指定日期的销售金额 = CALCULATE ( SUM ( Sales[Sales Amount] ), 'Sales'[OrderDateKey] = MAX ( 'Sales'[OrderDateKey] ) ) -
表表达式可以将表对象应用为筛选器。它可能是对模型表的引用,也可以是返回表对象的函数。可以使用 FILTER 函数来应用复杂的筛选条件,包括那些不能由 Boolean 表达式定义的条件。
-
Filter context 修改器函数不仅仅是添加筛选器,它们在修改筛选器上下文时还提供了额外的操作,例如
| 函数 | 使用目的 |
|---|---|
| REMOVEFILTERS | 删除所有筛选器,可以从表的一个或多个列中删除筛选器。 |
| ALL / ALLEXCEPT / ALLNOBLANKROW | 从一个或多个列或从单个表的所有列中删除筛选器。 |
| KEEPFILTERS | 添加筛选器,并且不删除相同列上的现有筛选器。 |
ALL 函数等既可以用作筛选器修改器,也可以充当返回表对象的函数。若 Power BI 版本支持 REMOVEFILTERS 函数,那么最好使用它来删除筛选器。
还有 CALCULATETABLE 函数,它执行完全相同的功能,只是它的作用是修改 Filter Context 中的表表达式。
下面的数据表计算了石家庄市的咖啡销售情况:
1
石家庄销售数量 = CALCULATE ( SUM ( '销售表'[数量] ), '城市'[地区] = "石家庄市" )
计算结果如下图所示:
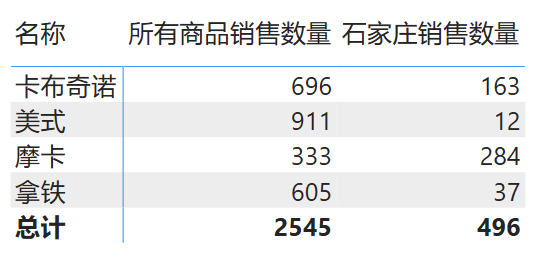
图 5: CALCULATE 函数示例 1 结果
下面的数据表计算了不同性别的销售量及其比例情况:
1
2
3
4
5
性别销售占比 =
DIVIDE (
SUM ( '销售表'[数量] ),
CALCULATE ( SUM ( '销售表'[数量] ), REMOVEFILTERS ( '性别'[顾客性别] ) )
)
计算结果如下图所示:
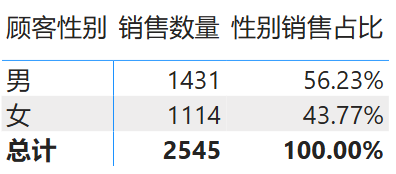
图 6: CALCULATE 函数示例 2 结果
下面的 DAX 的表达式定义了低成本商品和高成本商品,当商品成本 < 21.82 时定义该商品为低成本商品,否则定义该商品为高成本商品:
1
2
3
4
5
6
7
8
9
商品划分 =
IF (
CALCULATE (
AVERAGE ( '销售表'[成本] ),
ALLEXCEPT ( '商品表', '商品表'[杯型] )
) < 21.82,
"低成本商品",
"高成本商品"
)
在这个例子中,Row Context 转换成了 Filter Context,其中 AVERAGE 函数根据 Row Context 来计算平均成本,CALCULATE 函数通过参数的筛选条件实现对 Row Context 转换成 Filter Context。这就是所谓的 Context 转换,因此 CALCULATE 函数可以当作 Context 转换器。
EARLIER 函数
EARLIER 函数能够在回溯指定列的 Row Context 时返回上一个 Row Context 的值。EARLIER 函数通常用于多层嵌套的 CALCULATE 函数或者 FILTER 函数中,这能够帮助我们访问外层的 Row Context。
EARLIER 函数主要用于计算列中,它的语法如下:
1
EARLIER( <column>, <number> )
其中参数 column 是列名或者列表达式,number 是一个正数,表示要回溯的 Row Context 的层数,当number缺省时默认为 1。EARLIER 函数的返回值为指定列在回溯时在number处的行值。
若在表扫描开始之前有 Row Filter,则 EARLIER 函数执行成功,否则报错。
EARLIER 函数的执行性能很差。
下面的 DAX 表达式计算了每笔订单在总的销售数据中的排名情况:
1
2
3
4
5
6
排名 =
COUNTROWS (
FILTER ( '销售表',
EARLIER ( '销售表'[数量] ) < '销售表'[数量]
)
) + 1
与之类似的还有 EARLIEST 函数。
FILTER 系列函数
FILTER 函数
FILTER 函数用于过滤表格或列,生成满足特定条件的子集。其语法如下:
1
FILTER( <table>, <filter> )
其中参数table表示要过滤的表(也可以是表表达式),filter是 Boolean 表达式,返回值为一个满足条件的子表格。
FILTER 函数不能单独使用,而是作为嵌套函数,嵌入到需要表作为参数的其他函数中。
下面的数据表计算了除“美式”之外的咖啡销量:
1
除美式之外的销量 = SUMX ( FILTER ( '销售表', RELATED ( '商品表'[名称] ) <> "美式" ), '销售表'[数量] )
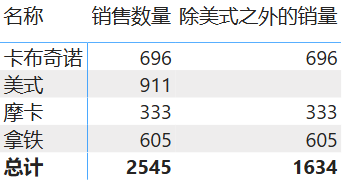
图 7: FILTER 函数示例结果
KEEPFILTERS 函数
值得一提的是,在 DAX 中要尽量避免使用 FILTER 函数作为筛选器参数!例如要计算“卡布奇诺”的销售成本,可以使用下面的 DAX 表达式进行计算:
1
卡布奇诺的销售成本 = CALCULATE ( [销售成本], FILTER ( '商品表', '商品表'[名称] = "卡布奇诺" ) )
CALCULATE 函数接受了 FILTER 函数返回的表表达式,该函数为商品表的每一行计算它的筛选器表达式。但是通过使用 Boolean 表达式可以更有效地实现这个需求:
1
卡布奇诺的销售成本 = CALCULATE ( [销售成本], KEEPFILTERS ('商品表'[名称] = "卡布奇诺" ) )
KEEPFILTERS 函数可以保留应用于名称列的任何现有筛选器,而不会被覆盖。
尽可能将筛选参数作为 Boolean 表达式传递。这是因为导入模型表是内存中的列存储,它们经过明确优化,可以以这种方式高效过滤列。但是如果遇到以下这几种是则必须使用 FILTER 函数:
- 无法引用来自多个表的列;
- 无法引用度量值;
- 无法使用嵌套 CALCULATE 函数;
- 无法使用扫描或返回表的函数。
REMOVEFILTERS 函数
REMOVEFILTERS 函数用于在计算过程中移除特定列或表的筛选器。它可以取消当前 Context 中的某些筛选器,使得度量值或计算结果在没有这些筛选器的情况下进行计算。
REMOVEFILTERS 函数的语法如下:
1
REMOVEFILTERS([<table> | <column>[, <column>[, <column>[,…]]]])
其中参数table是想要清除筛选器的表,column是想要消除筛选器的列。REMOVEFILTERS 函数不会返回任何值。
LOOKUPVALUE 函数
LOOKUPVALUE 函数可以根据某个条件返回一个表格中的指定列的值,与 Excel 中的 VLOOKUP 函数或者 HLOOKUP 函数类似。LOOKUPVALUE 函数也可以在不同表格之间进行查找和匹配。
它的语法如下:
1
2
3
4
5
6
7
LOOKUPVALUE (
<result_columnName>,
<search_columnName>,
<search_value>
[, <search2_columnName>, <search2_value>]…
[, <alternateResult>]
)
其中参数result_columnName表示要返回的值的现有列的名称,它不能是一个表达式;search_columnName是现有列的名称,它可以与 result_columnName在同一表中,也可以在相关的表中,同样它也不能是一个表达式;search_Value是在search_columnName中查找的值,可以指定多个search_columnName和search_value对;alternateResult表示发生错误时的指定返回值,如果未指定,则在查找时没有找到匹配的值时返回空值,在查找列中有多个相同的值是返回error。
如果结果列的表与搜索列的表之间存在关系,那么在大多数情况下,使用 RELATED 函数而不是 LOOKUPVALUE 会更高效,并且能提供更好的性能。
SELECTEDVALUE 函数
SELECTEDVALUE 函数用于从当前 Filter context 中获取列的唯一值。如果在 Context 中有多个值,它会返回一个默认值(如果指定了的话),否则会返回空值。
SELECTEDVALUE 函数的语法如下:
1
SELECTEDVALUE(<columnName>[, <alternateResult>])
其中参数columnName为现有列的名称,不能是表达式;alternateResult表示发生错误时的指定返回值,如果未指定,则在查找时没有找到匹配的值时返回空值,在查找列中有多个相同的值是返回error。
窗口函数
OFFSET 函数
在 SQL 中,LEAD 函数和 LAG 函数的语法形式如下:
1
2
LAG(expr [, N[, default]]) OVER ([PARTITION BY ...] [ORDERBY BY ... ASC|DESC ...] [ROWS|RANGE BETWEEN ... AND ...])
LEAD(expr [, N[, default]]) OVER ([PARTITION BY ...] [ORDERBY BY ... ASC|DESC ...] [ROWS|RANGE BETWEEN ... AND ...])
在 DAX 表达式中,OFFSET 函数配合 PARTITION 函数、ORDER 函数和 MATCHBY 函数,也可以实现 LEAD 函数和 LAG 函数的效果。OFFSET 函数的语法如下:
1
OFFSET ( <delta>[, <relation> or <axis>][, <orderBy>][, <blanks>][, <partitionBy>][, <matchBy>][, <reset>] )
其中参数delta表示在要从中获取数据的当前行之前(负值)或之后(正值)的行数。
下面解释 DAX 窗口函数中的固定参数:
partitionBy用于定义如何对relation进行分区的列,如果省略则被视为单个分区;orderBy是用来定义每个分区如何排序的表达式;matchBy用作定义如何匹配数据,以及标识当前行的列;relation表示返回输出行的表表达式,如果指定那么partitionBy中的所有列则必须全部来自于relation或者它的相关表,如果省略那么orderBy必须提供并且partitionBy的列名和orderBy的列名必须相同且来自于同一张表;blank是一个枚举,定义在对relation或axis排序时如何处理空值;axis表示 visual shape 的 axis,仅在可视化计算中使用,用来替代relation;reset指示计算是否重置以及在 visual shape 的列层次结构的哪个级别上重置,仅在可视化计算中使用。
relation参数通常使用 SELECTCOLUMNS 函数提取单列。
RANK 函数
在 SQL 中,RANK 函数的语法形式如下:
1
RANK() OVER ([PARTITION BY ...] [ORDERBY BY ... ASC|DESC ...] [ROWS|RANGE BETWEEN ... AND ...])
在 DAX 表达式中,RANK 函数配合 PARTITION 函数、ORDER 函数和 MATCHBY 函数,也可以实现 RANK 函数的效果。RANK 函数的语法如下:
1
RANK ( [<ties>][, <relation> or <axis>][, <orderBy>][, <blanks>][, <partitionBy>][, <matchBy>][, <reset>] )
其中参数ties用作定义在两行或多行并列时如何处理排序,可分为“DENSE 模式”或者“SKIP 模式”(默认)。
ROWNUMBER 函数
在 SQL 中,ROW_NUMBER 函数的语法形式如下:
1
ROW_NUMBER() OVER ([PARTITION BY ...] [ORDERBY BY ... ASC|DESC ...] [ROWS|RANGE BETWEEN ... AND ...])
在 DAX 表达式中,ROWNUMBER 函数配合 PARTITION 函数、ORDER 函数和 MATCHBY 函数,也可以实现 ROWNUMBER 函数的效果。ROWNUMBER 函数的语法如下:
1
ROWNUMBER ( [<relation> or <axis>][, <orderBy>][, <blanks>][, <partitionBy>][, <matchBy>][, <reset>] )
其中参数delta表示在要从中获取数据的当前行之前(负值)或之后(正值)的行数。
WINDOW 函数
在 SQL 中,NTILE 函数的语法如下:
1
NTILE(N) OVER ([PARTITION BY ...] [ORDERBY BY ... ASC|DESC ...] [ROWS|RANGE BETWEEN ... AND ...])
在 DAX 表达式中,WINDOW 函数配合 PARTITION 函数、ORDER 函数和 MATCHBY 函数,也可以实现 WINDOW 函数的效果。WINDOW 函数的语法如下:
1
WINDOW ( from[, from_type], to[, to_type][, <relation> or <axis>][, <orderBy>][, <blanks>][, <partitionBy>][, <matchBy>][, <reset>] )
其中参数from和to表示窗口的起始/结束位置;若from_type或者to_type为REL,则表示从当前行向后移动(负值)或向前移动(正值)以获得窗口中的第一行的行数,若from_type或者to_type为ABS,并且from是正数,那么它是窗口的开始距离分区的开始的位置。
INDEX 函数
在 SQL 中,NTH_VALUE 函数的语法如下:
1
NTH_VALUE(expr, N) OVER ([PARTITION BY ...] [ORDERBY BY ... ASC|DESC ...] [ROWS|RANGE BETWEEN ... AND ...])
在 DAX 表达式中,INDEX 函数配合 PARTITION 函数、ORDER 函数和 MATCHBY 函数,也可以实现 INDEX 函数的效果。INDEX 函数的语法如下:
1
INDEX( <position>[, <relation> or <axis>][, <orderBy>][, <blanks>][, <partitionBy>][, <matchBy>][, <reset>] )
其中参数position表示获取数据的绝对位置。若position为正数,则 1 表示第一行,2 表示第二行等;若position为负数,则 -1 表示最后一行,-2 表示倒数第二行等等;如果位置超出边界、空值或者没有匹配到值,INDEX 函数将返回一个空表。
可视化计算函数
以下函数仅能使用在可视化计算中!
MOVINGAVERAGE 函数
MOVINGAVERAGE 函数会沿视觉对象计算数据网格的指定轴计算移动平均值,这对于时间序列分析十分有用。其语法如下:
1
MOVINGAVERAGE ( <column>, <windowSize>[, <includeCurrent>][, <axis>][, <blanks>][, <reset>] )
其中参数column表示为每个元素提供值的列。
下面解释 DAX 可视化计算函数中的固定参数:
windowSize表示计算中要包括的行数,必须是常量值;includeCurrent指定是否将当前行包含在范围内,默认为TRUE;axis用作计算移动平均值的方向;blank是一个枚举,定义在排序时如何处理空值。
FIRST 函数与 LAST 函数
FIRST 函数可以从轴的第一个元素检索视觉矩阵中的值,而 LAST 函数可以从轴的最后一个元素检索视觉矩阵中的值。它们的语法如下:
1
2
3
FIRST ( <column>[, <axis>][, <blanks>][, reset] )
LAST ( <column>[, <axis>][, <blanks>][, reset] )
其中参数column表示需要要检索的列。
PREVIOUS 函数与 NEXT 函数
PREVIOUS 函数可以读取视觉矩阵中某一坐标轴前一个元素的值,而 NEXT 函数可以读取视觉矩阵中某一坐标轴后一个元素的值。它们的语法如下:
1
2
3
PREVIOUS ( <column>[, <steps>][, <axis>][, <blanks>][, reset] )
NEXT ( <column>[, <steps>][, <axis>][, <blanks>][, reset] )
其中参数column表示需要要检索的列。
RANGE 函数
RANGE 函数能够返回给定轴内相对于当前行的行间隔,这个间隔要么由当前步骤之前的最后一个step行组成,要么由当前步骤之后的第一个step行组成。
RANGE 函数的语法如下:
1
RANGE ( <step>[, <includeCurrent>][, <axis>][, <blanks>][, <reset>] )
其中参数step是在要包含在范围中的当前行之前(负值)或之后(正值)的行数,必须是一个常数。
RUNNINGSUM 函数
RUNNINGSUM 函数返回沿可视化矩阵的给定轴计算的运行和,也就是说RUNNINGSUM 函数可以计算给定列在所有元素上的总和,直到 axis 的当前元素。
RUNNUNGSUM 函数的语法如下:
1
RUNNINGSUM ( <column>[, <axis>][, <blanks>][, <reset>] )
其中参数column为每个元素提供值的列。