

Power BI 是一款功能强大的商业智能软件,在当下的数据分析领域占据着重要地位。它就像是 Excel 的升级版,不过功能更为全面且强大,已然成为数据处理与分析方面的得力助手。Power BI 由三部分组成:Power Query、Power Pivot 和 Power View。
Power Query 用来获取文件、文件夹、数据库、网页等数据并进行深度加工处理,然后把这些处理步骤进行保存,后期数据更新时无须再次重复操作。Power Query 有可视化的操作界面,同时支持用 M 语言进行高级编辑。
Power Pivot 可以利用 Power Query 处理好的数据或其他数据建立分析维度,实现模型搭建。Power Pivot 使用 DAX 语言进行函数编辑,DAX 具有与 Excel 函数相似的编辑方式。
Power View 则是 Power BI 强大的可视化模块,内置条形图、直方图、折线图、散点图和饼图等基本图形,还包括瀑布图、漏斗图、树状图、桑基图等高级图形,除此之外 Power View 能够从外部导入各式各样的图表。
Power Query
Power Query 是 Power BI 实现数据 ETL(Extract-Transform-Load)的重要工具,它使得用户能够轻松地从各种数据源提取数据,并对其进行转换和清洗,最终加载到 Power BI 中进行分析和可视化。通过 Power Query,用户可以执行数据合并、过滤、格式转换、分列等操作,支持对多个数据源的连接和处理。
数据规范化
有时候由于 Power Query 识别失败的原因,数据集的第一行并不会作为列名,这是就需要我们手动设置“将第一行作为标题”命令。
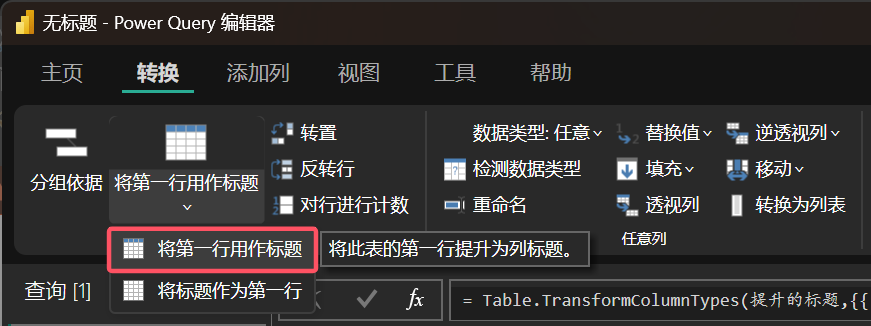
图 1: 将第一行作为标题
格式转换
在字段的左侧会看到数据类型的下拉按钮,单击此按钮在下拉列表就直接可以选择修改数据类型。除了手动修改字段的数据类型,Power Query 还支持自动检测字段的数据类型。
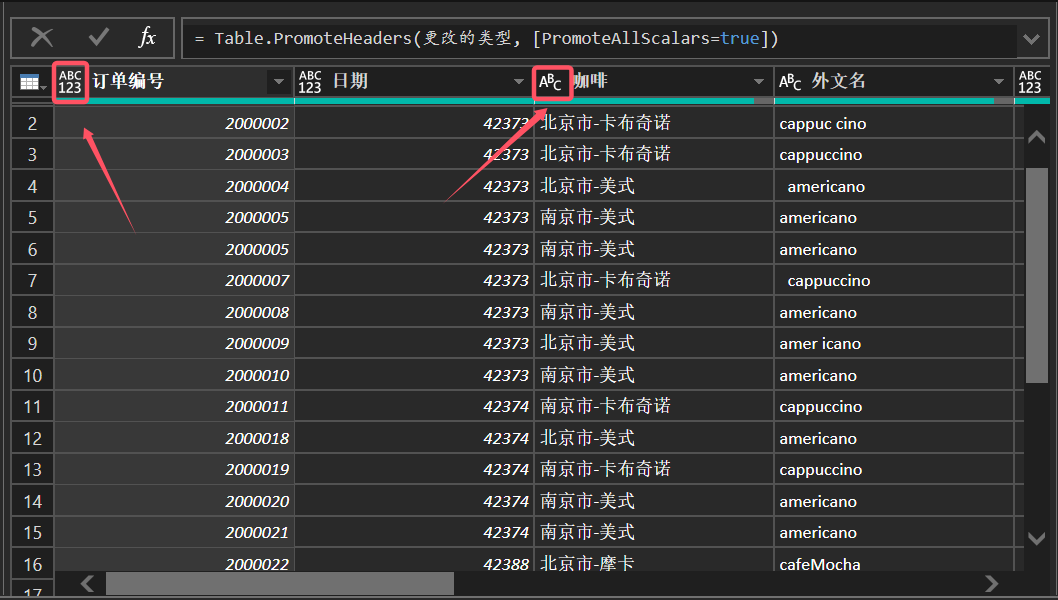
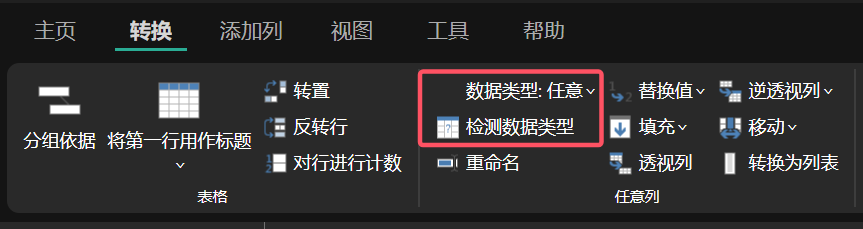
图 2: 修改数据类型
数据清洗
当我们想要删除数据集中的重复值、空值和 Error 值等时,可以在“删除行”中进行选择。
需要指出的是,只有当某一行的所有字段都与其他行重复,或者都为空值时,“删除行”的命令才会起作用;当某一行的字段存在 Error 值时,该行就会被删除。
当选择某一字段时,执行“删除行”命令则会保留该列的唯一值或者非空值。删除空值的方法还可以直接对字段进行筛选。
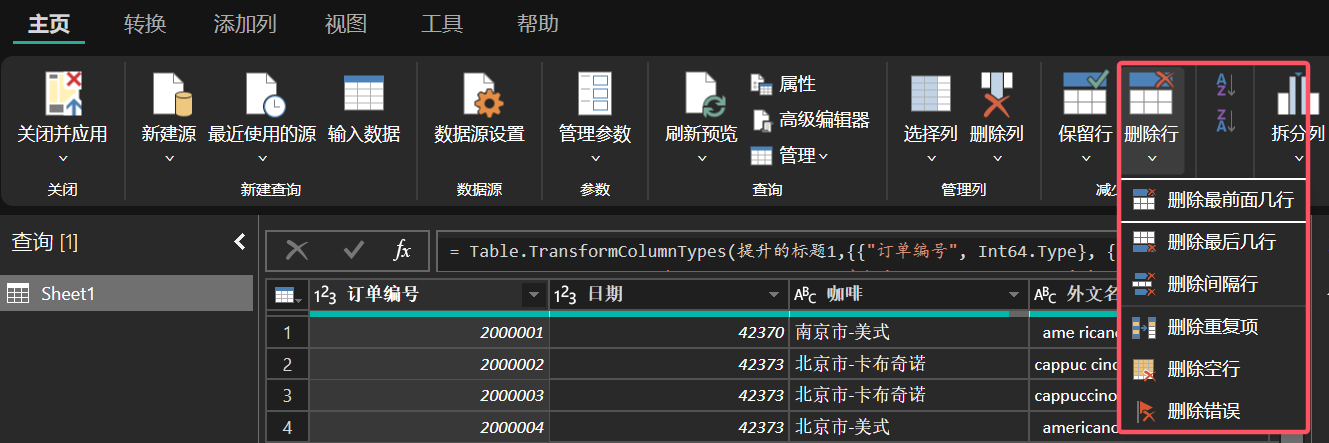
图 3: 删除重复值、空值和 Error 值
对于缺失值的处理,可以选择“填充”命令,向上或者向下填充缺失值。Power Query 有着很强的扩展性,可以选择直接执行 Python/R 脚本选择符合我们需求的缺失值填充方式。
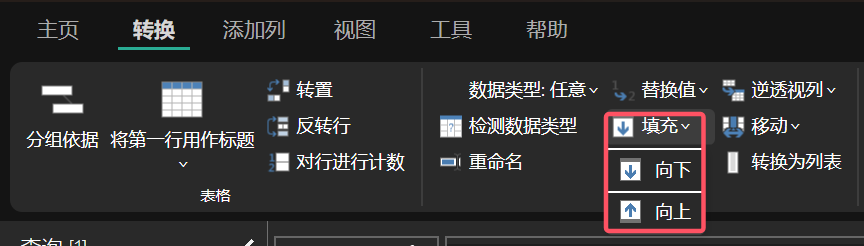
图 4: 填充缺失值
有时候我们需要替换数据集中的某些文本内容,这就可以使用“替换值”命令进行替换。
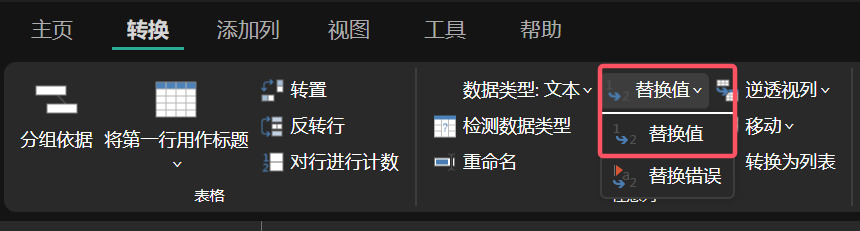
图 5: 内容替换
除此之外,我们还可以在“格式”命令中对字段中的英文进行转换。
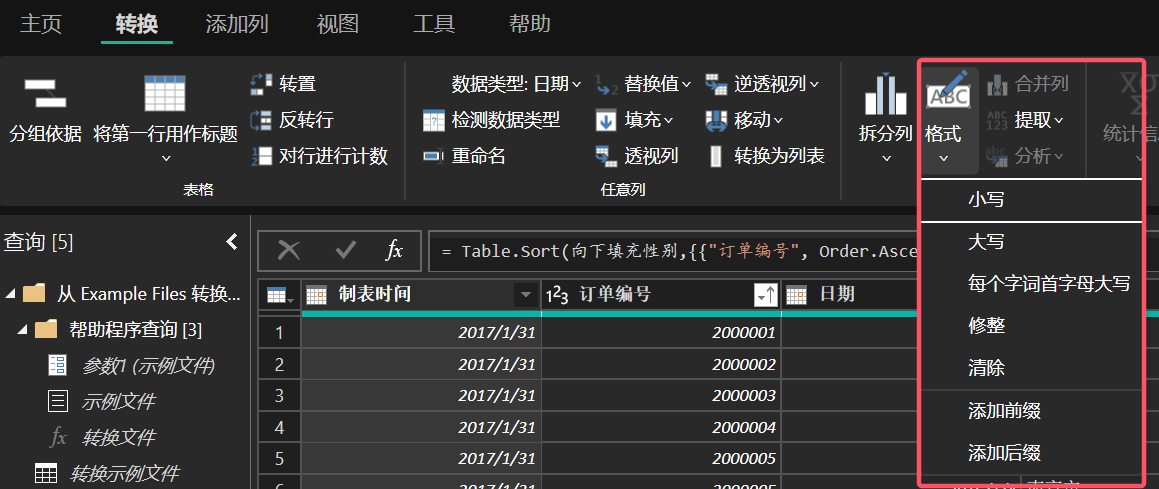
图 6: 对字段中的英文进行操作
字段拆分合并
在数据清洗过程中,对字段进行拆解合并也是一项十分重要的步骤,这些操作都可以在 Power Query 的“拆分列”和“合并列”选项实现。其中“拆分列”命令支持按分隔符、字符数和指定位置对字段进行拆分。
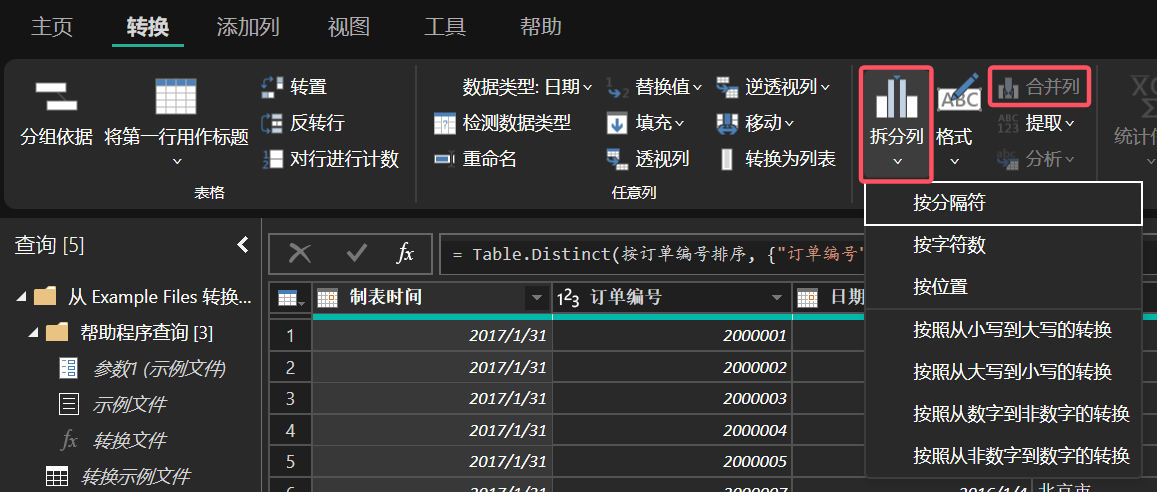
图 7: 对字段进行拆分合并
Power Query 还能够根据我们的需求提取字段的内容。
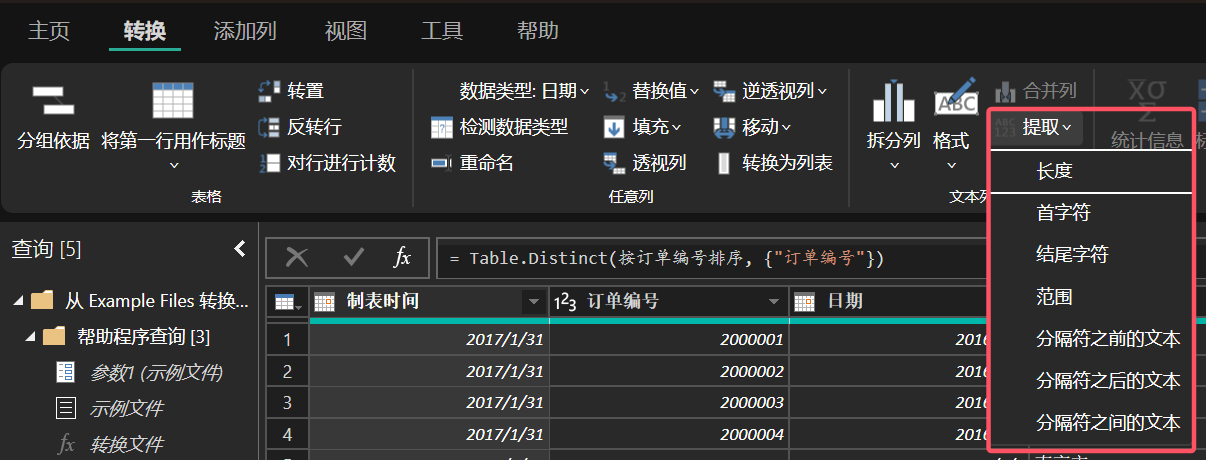
图 8: 对字段的值进行提取
统计聚合
“分组依据”命令可以按照字段和聚合类型,对数据进行分组统计操作。
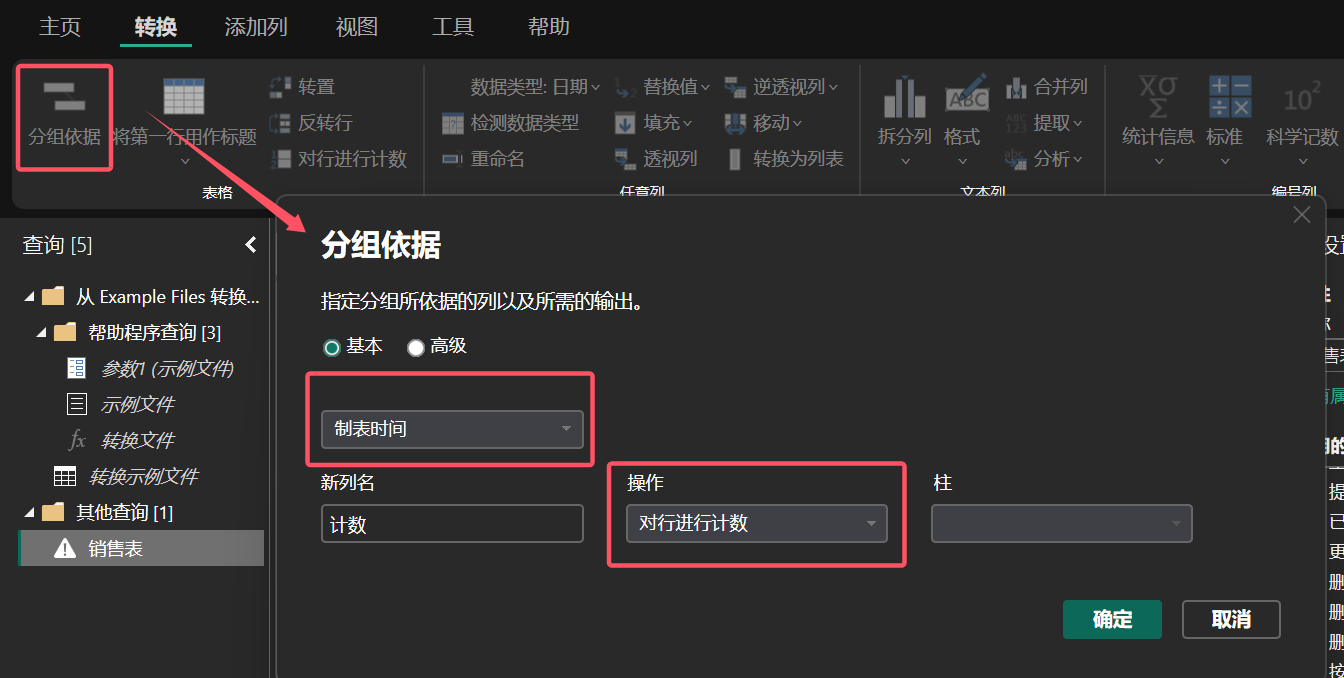
图 9: 分组聚合统计
另外在 Power Query 中,还可以制作透视表和逆透视表。透视表就是一张二维的列联表,而逆透视表就是将二维列联表转换成一维表。
例如一张二维列联表,它的行是不同的咖啡种类,列是不同的杯型。那么该二维列联表的逆透视表就是一张包含[咖啡种类、杯型、数量]的一维表。
图 10: 透视表与逆透视表
若想制作一张“咖啡种类——杯型”的逆透视表,只需选中关于杯型字段的“大杯数量”、“中杯数量”和“小杯数量”,然后选择“逆透视列”即可;反过来若想制作“咖啡种类——杯型”的透视表,只需选中“杯型”字段,然后选中“透视列”即可。
衍生列计算
在 Power Query 中,“添加列”命令可以在现有数据的基础上创建新的列,这些新列可以是基于现有列的计算结果、条件逻辑或其他数据处理操作。通过“添加列”命令,可以扩展数据集并生成新的指标,从而为后续的分析和建模提供更多的洞察力。
“添加列”命令支持“条件列”、“索引列”、“自定义列”和“示例列”。“条件列”类似于 Excel 中的IF函数,可以设置多个条件,并为每个条件指定对应的输出值。
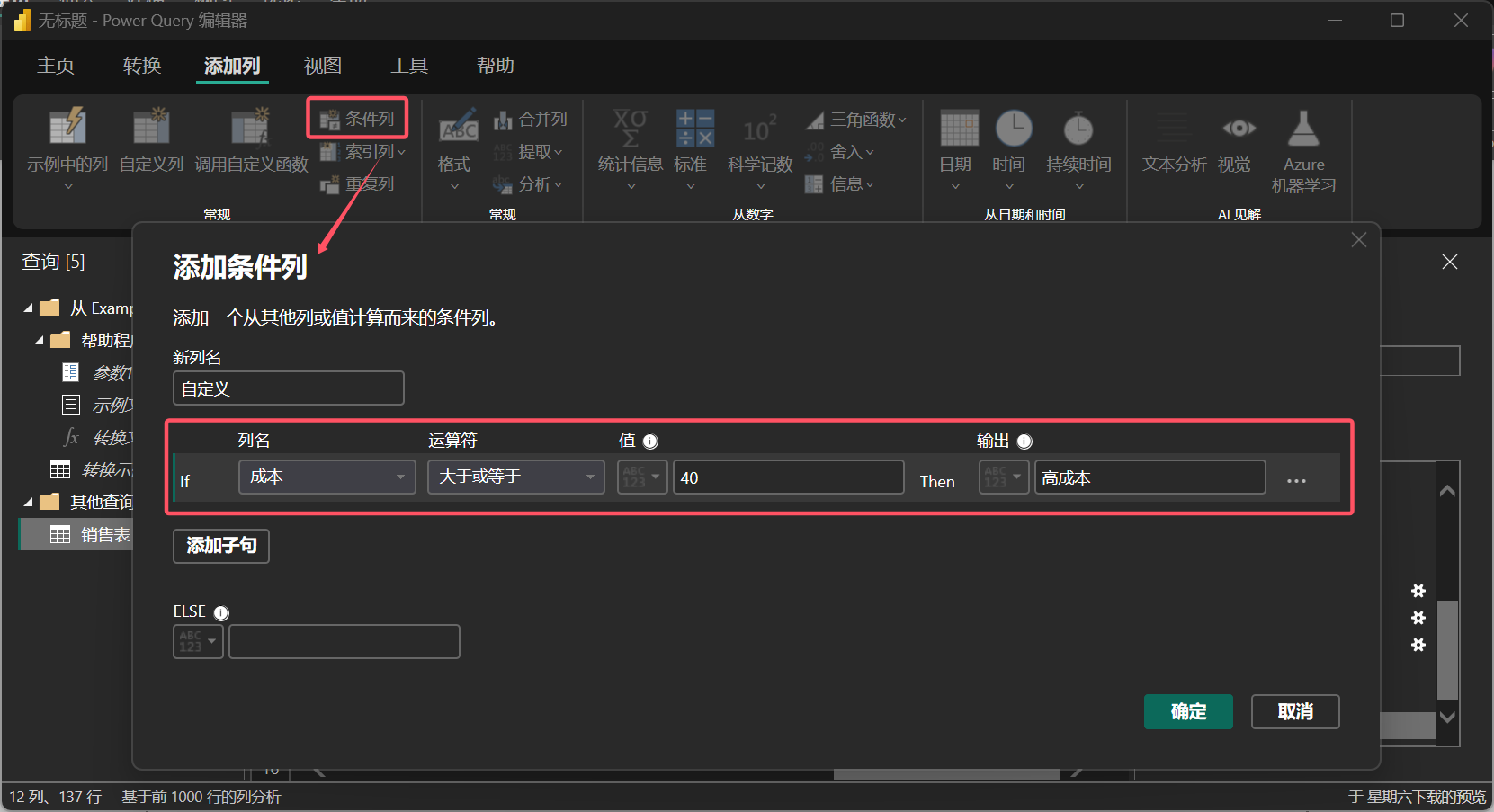
图 11: 条件列
“索引列”用于为数据集中的每一行分配一个唯一的编号,这个编号可以是从 0 开始、从 1 开始,也可以根据已有的列进行递增或递减。
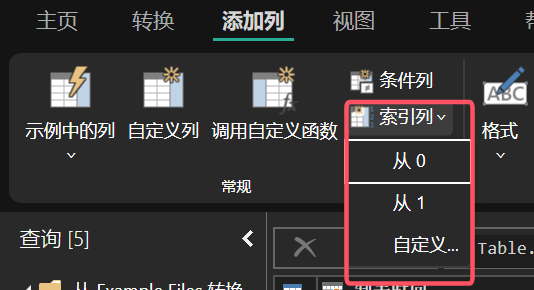
图 12: 索引列
“示例列”是是一个智能功能,只需输入满足需求的值,之后 Power Query 会解决后续的操作问题。例如在“城市”字段中想提取“市”之前的城市名,那么只需在第一行内输入“北京”,然后会看到整个列都出现了想要的结果了。
“自定义列”则是通过自定义公式或表达式,可以基于现有列的数据进行计算生成新的列。这种列的计算通常是基于 M 语言来实现的,可以包括数学运算、文本操作、日期计算等。
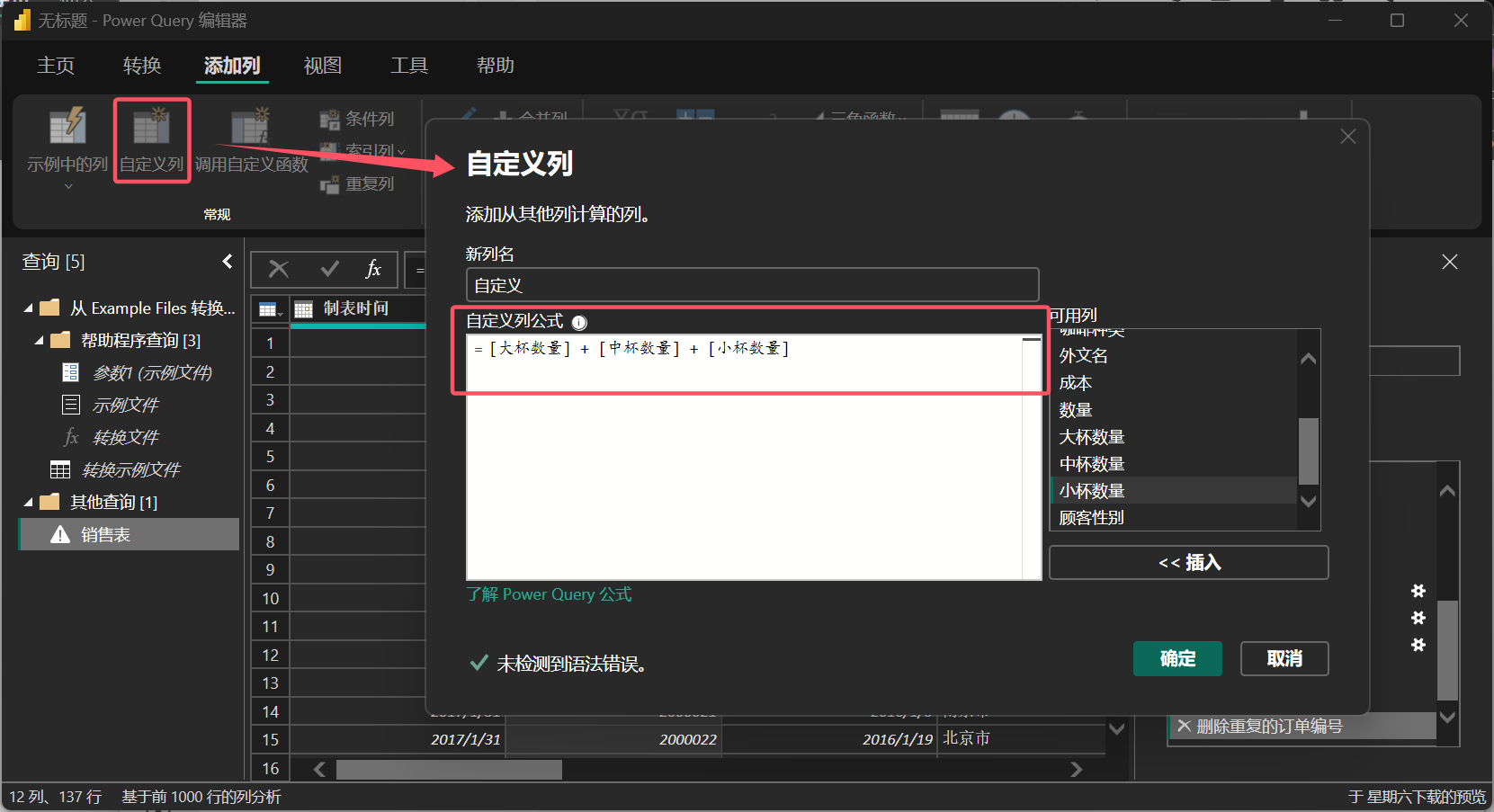
图 13: 自定义列
日期/时间操作
Power Query 中的“日期”和“时间”命令可以设置“日期”/“时间”值格式或提取”日期”/“时间”值的元素,“持续时间”命令可以设置“持续时间”值的格式。

图 14: 日期&时间列
数据合并
在某些情况下,我们需要在数据表中添加另一张数据表的字段,这时可以使用“合并查询”。它能够将两个或多个查询中的数据按照某些公共字段进行合并,相当于 SQL 中的 JOIN 操作。合并后的结果是一个包含来自不同查询的相关信息的新数据表。该功能非常适合处理需要从多个数据源或多个表中提取相关信息的情况。
合并查询中两张数据表的连接方式与 SQL 中的 JOIN 操作类似,需要设置左连接、右连接、内连接以及全连接。

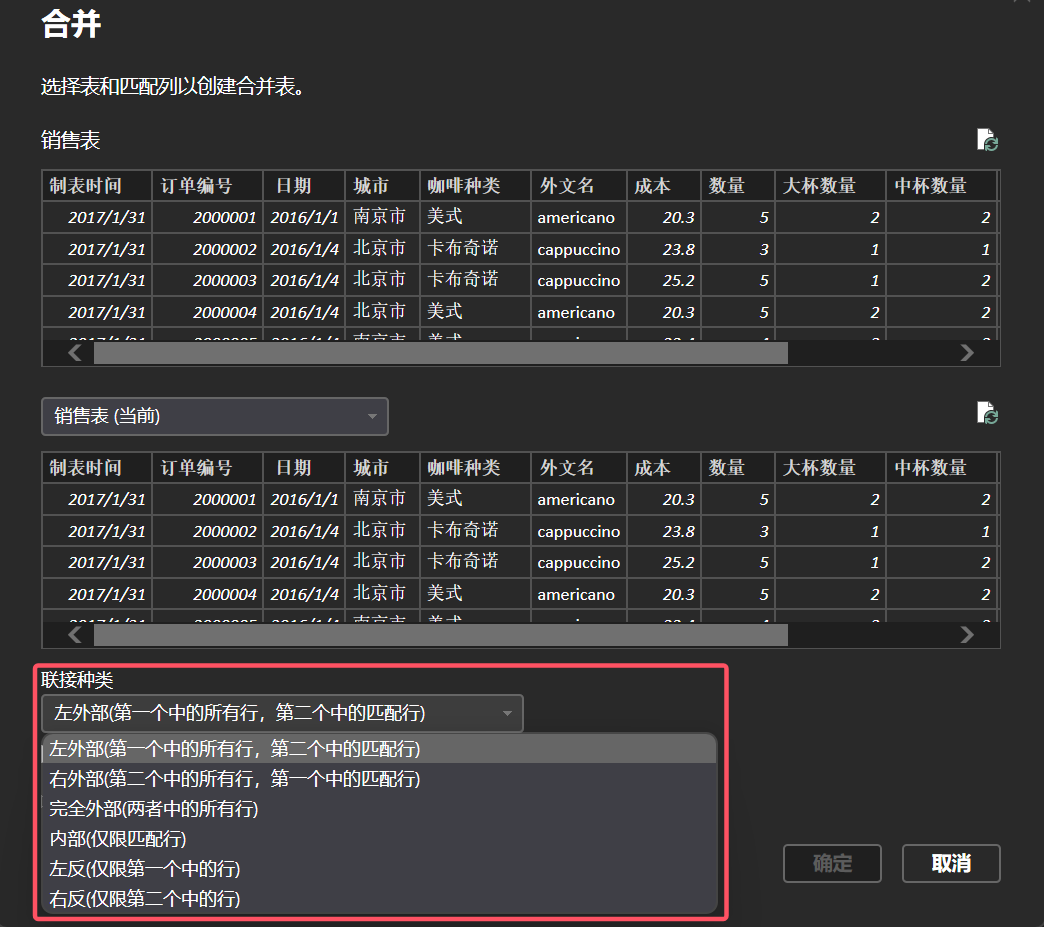
图 15: 合并查询
除了合并查询之外,还能够想数据表的纵向追加数据行,这可以通过“追加查询”命令完成。注意,这需要两张表的字段完全相同!


图 16: 追加查询
汇总数据集
Power Query 允许批量导入文件夹的数据集,后续只需往文件夹中添加新的文件即可,Power Query 会自动更新数据。
flowchart LR
A@{ shape: circle, label: 获取数据 }
B@{ shape: documents, label: 选择从“文件夹” }
C@{ shape: rect, label: 输入目标文件夹路径 }
D@{ shape: rounded, label: 下拉“组合”选项 }
E@{ shape: rounded, label: 选择“合并并转换数据” }
F@{ shape: processes, label: 进行数据 ETL 流程 }
A --> B --> C --> D --> E --> F
但是需要注意的是,文件夹下的数据集的格式必须保持一致,否则 Power Query 会因为格式混乱而报错。
Power View
Power View 是 Power BI 中的一项强大的数据可视化功能,它为用户提供了一种互动式的方式来创建、查看和分享动态的报表和仪表板。通过 Power View,用户能够通过直观且交互式的图表和图形,将数据转化为具有洞察力的视觉表现,从而帮助更好地理解数据并做出决策。
Power View 允许用户与报告进行深度交互,包括:
- 筛选与切片:用户可以通过筛选条件和切片器选择数据的不同子集,动态更新视图;
- 钻取(Drillthrough):通过点击图表或表格中的特定数据点,用户可以进一步查看该数据点的详细信息;
- 联动视图:不同的可视化组件之间会联动,用户与一个图表的互动会自动更新其他相关图表,帮助用户更深入地挖掘数据。
Power Pivot
Power Pivot 是 Power BI 中的核心组件之一。它是一种数据建模工具,能够帮助用户处理和分析大量数据,建立复杂的数据关系模型,并支持高效的计算与分析。Power Pivot 可以处理几百万行数据,并且支持创建多表之间的关系,执行复杂的计算,最终帮助用户生成高效的商业智能分析报告。
数据模型
在数据仓库的建设过程中,根据事实表与维表的关系,经常将数据模型分为星型模型、雪花模型及星座模型。
星型模型
星型模型中只有一张事实表,以及 0 张或多张维表,事实表与维表通过主键外键相关联,维表之间不存在关联关系,当所有维表都关联到事实表时,整个图形非常像一种星星的结构,所以称之为“星型模型”。
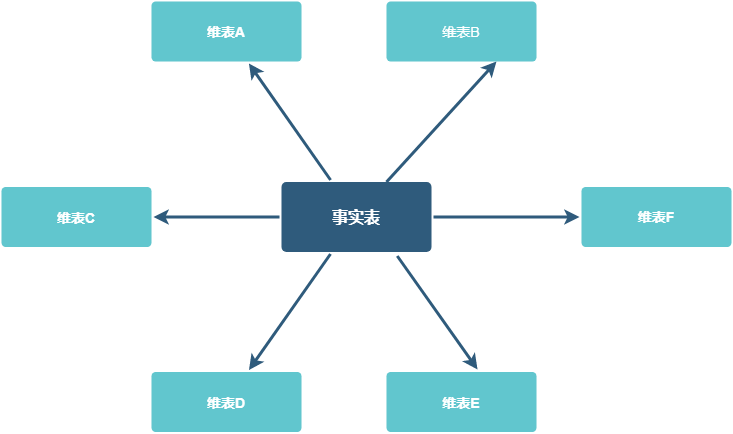
图 17: 星型模型
星型模型是最简单最常用的模型。星型模型本质是一张大表,相比于其他数据模型更合适于大数据处理。其他模型可以通过一定的转换,变为星型模型。
星型模型的缺点是存在一定程度的数据冗余。因为其维表只有一个层级,有些信息被存储了多次。
雪花模型
当一个或多个维表没有直接连接到事实表上,而是通过其他维表连接到事实表上时,其图解就像多个雪花连接在一起,故称雪花模型。雪花模型是对星型模型的扩展。它对星型模型的维表进一步层次化,原有的各维表可能被扩展为小的事实表,形成一些局部的”层次”区域,这些被分解的表都连接到主维表而不是事实表。
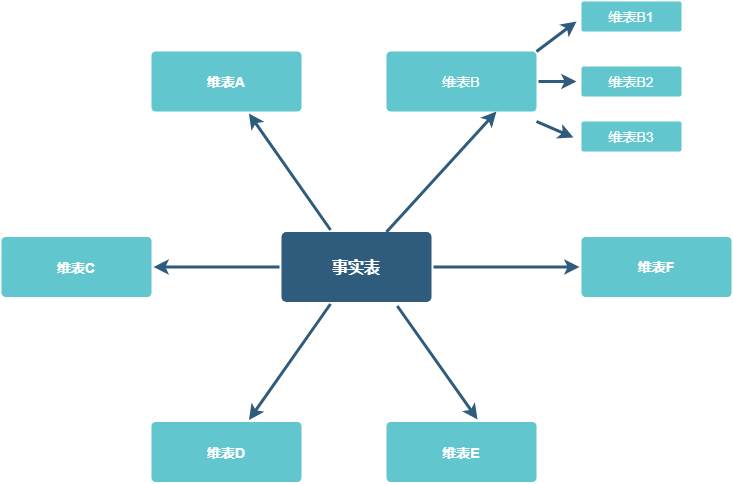
图 18: 雪花模型
其优点是通过最大限度地减少数据存储量以及联合较小的维表来改善查询性能,避免了数据冗余。其缺点是增加了主键-外键关联的几率,导致查询效率低于星型模型,并且不利于开发。
星座模型
星座模型也是星型模型的扩展。区别是星座模型中存在多张事实表,不同事实表之间共享维表信息,常用于数据关系更复杂的场景。其经常被称为星系模型。
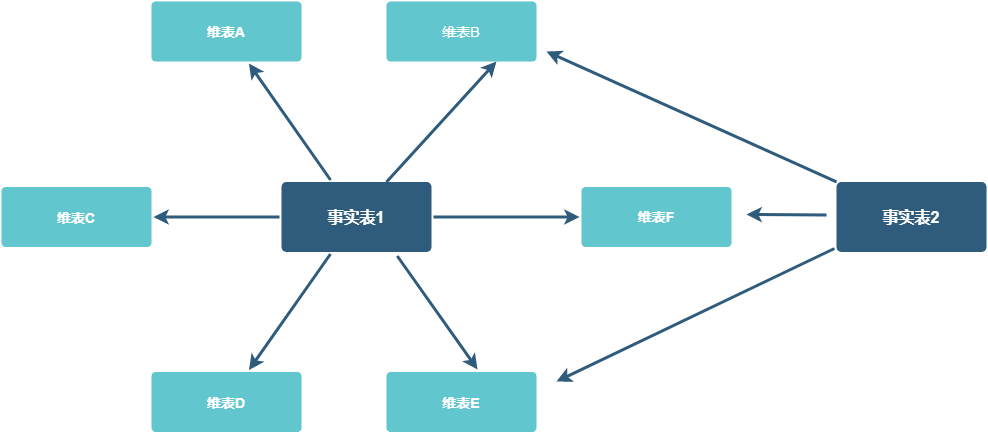
图 19: 星座模型
数据分析表达式
DAX(Data Analysis Expression)是一种功能强大的数据建模和分析公式语言。DAX 可以从模型中已有的数据中创建新信息,它用于创建计算列、度量值、计算表以及在数据模型中进行高级数据分析和聚合,允许用户在数据模型中创建复杂的计算、度量值和数据分析,帮助用户高效处理和分析数据。
DAX 的核心功能包括:
- 计算列和度量值:可以基于现有数据创建新的计算列或度量值;
- 时间智能:支持强大的时间序列分析,如环比、同比增长等;
- 筛选与上下文修改:通过 CALCULATE 函数等修改数据上下文,进行条件计算和聚合;
- 表格操作:能够执行复杂的表格过滤和聚合,例如使用 FILTER 函数和 SUMMARIZE 函数等生成自定义的计算表。
DAX 使用户能够在数据模型中进行动态计算,提供了深度的数据分析能力以及更强的功能和灵活性,特别适合在商业智能工具中执行实时的数据分析和报表制作。
度量值
Power Pivot 将指标(Indicator)定义成度量值(Measures),也被称作计算字段(Calculated fields)。与度量值类似的是计算列(Caltulated columns),度量值与计算列都是由 DAX 编写。
它们二者的区别如下表所示:
| 计算列 | 度量值 | |
|---|---|---|
| 计算方式 | 按行计算数据。 每一行的数据都有一个计算结果,结果存储在模型中。 |
根据筛选条件和聚合的 Context 动态计算结果。 计算结果不会存储,而是根据用户的筛选条件实时计算。 |
| 存储位置 | 结果存储在数据模型中,作为表的一部分。 | 结果不存储,而是在查询时动态计算,并且只在需要时进行计算。 |
| 计算粒度 | 每行数据都有一个计算结果,通常是与其他列的值相关。 | 结果通常是聚合的,依赖于筛选条件或透视表的 Context。 |
| 使用场景 | 用于将每行的计算结果作为新列添加到数据模型中, 适用于每一行需要单独处理的计算。 |
用于聚合计算, 适用于需要在报表或透视表中显示的汇总数据。 |
| 更新方式 | 计算列的值在数据加载时计算,并存储在数据模型中。 | 度量值的计算是在查询时动态计算的,因此不会占用存储空间。 |
| 性能 | 对于大数据集,计算列可能会增加模型的大小, 它将结果存储在数据模型中。 |
度量值只在查询时计算,不增加存储大小。 对于较大的数据集,通常性能较好。 |
总之,计算列适用于按行计算的场景,通常用于为数据表添加新的列,计算过程在数据加载时完成,并且结果被存储;度量值适用于需要聚合和根据 Context 动态计算的场景,通常用于报告和透视表中进行汇总计算,计算过程在查询时按需进行。
上下文
上下文(Context)是理解 DAX 的核心概念,它直接影响着数据的计算、呈现以及交互方式。简单来说 Context 就是 DAX 所处的外部环境,它又分为筛选上下文和行上下文。
筛选上下文(Filter context)是指对数据集应用的筛选条件。它通常由切片器、行/列维度、度量值、以及其他视觉对象中的选择所决定。简单来说 Filter context 就是对字段进行筛选。
在 Power BI 中,度量值是最常依赖 Filter context 的元素。当你选择报表中的某个筛选条件或维度时,这些筛选条件会影响度量值的计算,进而改变报表中的结果。
DAX 中的表函数,例如 FILTER 函数、ALL 函数等,都是基于 Filter context 进行操作的。
所有度量值都可以看作是 Filter context 的函数。
而行上下文(Row context)是指对每一行数据进行计算时产生的 Context。它通常出现在计算列中。在每一行添加计算时,DAX 引擎会自动为每一行提供 Row context。简单来说 Row context 就是对表进行迭代。
DAX 中的迭代函数,例如 SUMX 函数、AVERAGEX 函数等,都是基于 Row context 进行操作的。
CALCULATE 函数可以将 Row context 转换为 Filter context。
在某些情况下,Row context 和 Filter context 可能会结合在一起。在 Power BI 中,DAX 的计算是动态的,它们会基于当前的上下文来调整结果。
例如在使用 CALCULATE 函数时,DAX 会在现有的 Filter context 基础上修改或添加筛选条件,进而影响度量值的计算。DAX 中的一些函数(如 EARLIER 函数)会在 Row context 和 Filter context 之间进行转换。
筛选器
Power BI 中的筛选器(filters)是用来限制报表中显示的数据的机制。它们允许用户专注于数据集的特定部分,无论是通过可视化、页面还是报表,并有助于确保得出的见解与当前 Context 或分析相关。
筛选器分为下面几种类型:
- 视觉级筛选器(Visual-Level Filters): 这些筛选器仅适用于报告页面上的单个视觉效果。它们有助于缩小特定图表、表格或其他可视化中显示的数据范围。例如有一个按地区显示销售额的条形图,视觉级筛选器可能会限制数据,只显示销售额超过某个阈值的地区;
- 页面级筛选器(Page-Level Filters):这些筛选器适用于特定报告页面上的所有可视化数据。当我们想在一个页面中创建多个可视化数据的集中视图时,这些筛选器非常有用。例如在销售仪表板上,可以使用页面级筛选器在该页面的所有图表中显示特定年份的数据;
- 报告级筛选器(Report-Level Filters):这些筛选器会影响整个报告中的每个页面和可视化效果。它们通过应用统一的筛选器来确保整个报表数据的一致性。例如报告级过滤器可用于将整个报告限制为特定业务部门或国家的数据;
- 切片器(Slicers): 切片是交互式可视元素,可用作屏幕上的筛选器。用户可通过点击切片选项动态过滤报告。例如切片器可以让用户选择一个或多个产品类别,并立即更新页面上的所有可视化内容,以反映用户的选择。
DAX 表达式
变量
在编写 DAX 表达式时,使用变量可以避免重复书写相同的表达式,并大大提高代码的可读性。例如:
VAR TotalSales = SUM( Sales[SalesAmount] )
VAR TotalCosts = SUM( Sales[TotalProductCost] )
VAR GrossMargin = TotalSales - TotalCosts
RETURN
GrossMargin / TotalSales变量由 VAR 关键字定义。在定义了一个变量之后,需要提供一条 RETURN 语句来定义表达式的结果值。还可以一次定义多个变量,这些变量属于定义它们的表达式的局部变量。
在表达式中定义的变量不能在表达式自身之外使用。也就是说表达式中不存在全局变量这意味着你不能定义适用于整个模型的变量。
变量使用 Lazy 计算,即假设你定义了一个变量,无论出于什么原因如果没有被使用,那么这个变量将永远不会被计算。如果需要计算,那么计算只会发生一次一后续对变量的调用都将读取先前计算出的值。
因此当多次使用复杂的表达式时,定义变量也可以作为一种优化技术。
聚合函数
| 函数 | 解释 |
|---|---|
| APPROXIMATEDISTINCTCOUNT | 返回列中唯一值的估计值。 |
| AVERAGE / AVERAGEA | 返回一列中所有数字的算术平均值,后者能够处理文本和非数字值。 |
| COUNT / COUNTA | 计算指定列中包含非空值的行数,后者能够处理文本和非数字值。 |
| COUNTBLANK | 计算列中空白单元格的数量。 |
| COUNTROWS | 计算指定表或表达式定义的表中的行数。 |
| DISTINCTCOUNT / DISTINCTCOUNTNOBLANK | 计算列中不同值的数量,后者不包括空白单元格。 |
|
MAX /
MAXA MIN / MINA |
返回一列中或两个标量表达式之间的最大/小值,后者能够处理文本和非数字值。 |
| PRODUCT | 返回某列中数字的乘积。 |
| SUM | 将一列中的所有数字相加。 |
日期与时间函数
| 函数 | 解释 |
|---|---|
| CALENDAR / CALENDARAUTO | 返回一个名为“Date”的单列表,该列包含一个连续的日期集。 |
| DATE | 返回指定的日期。 |
| DATEDIFF | 返回两个日期之间的间隔天数。 |
| DATEVALUE | 将文本格式的日期转换为日期时间格式的日期。 |
|
YEAR /
QUARTER /
MONTH /
WEEKDAY/ DAY / HOUR / MINUTE / SECOND |
返回月份中的年份/季度/月份/星期数/天数/小时数/分钟数/秒数。 |
| EDATE | 返回距离起始日期指定月数之前或之后的日期。 |
| EOMONTH | 返回指定月份之前或之后的最后一天。 |
| NETWORKDAYS | 返回两个日期之间的完整工作日数量。 |
| NOW / TODAY | 返回当前日期和时间。 |
| TIME | 将给定的小时、分钟和秒数转换为日期时间格式的时间。 |
| TIMEVALUE | 将文本格式的时间转换为日期时间格式的时间。 |
| UTCNOW / UTCTODAY | 返回当前 UTC 日期和时间。 |
| WEEKNUM | 根据返回类型的值,返回给定日期和年份的周数。 |
| YEARFRAC | 计算两个日期之间的完整天数所代表的年份的分数。 |
筛选函数
| 函数 | 解释 |
|---|---|
| ALL | 忽略任何可能已应用的筛选器,并返回所有行或列中的所有值。 |
| ALLCROSSFILTERED | 清除所有应用于表的筛选器。 |
| ALLEXCEPT | 清除应用于指定列外的 Filter context。 |
| ALLNOBLANKROW | 忽略可能存在的 Filter context,并返回除空白行以外的所有行,或除空白行以外的列的所有不同值。 |
| ALLSELECTED | 删除当前查询中列和行的 Filter context,同时保留所有其他 Filter context 或显式筛选器。 |
| CALCULATE / CALCULATETABLE | 修改 Filter Context 中的表达式或者表表达式。 |
| EARLIER / EARLIEST | 从当前 Row context 的上一级 Row context 中返回列的标量值。 |
| FILTER | 返回表示另一个表或表达式子集的表。 |
| FIRST / LAST | 从坐标轴的第一行/最后一行读取可视化矩阵中的数值,仅用于可视化计算。 |
| INDEX | 返回指定分区中由位置参数指定的绝对位置上的一行,并按指定顺序或指定坐标轴排序。 |
| KEEPFILTERS | 修改 CALCULATE 或 CALCULATETABLE 函数在应用筛选器的方式。 |
| LOOKUPVALUE | 返回符合搜索条件指定的所有条件的行值,该函数可以应用一个或多个搜索条件。 |
| MATCHBY | 在窗口函数中,定义用于确定如何匹配数据和识别当前行的列。 |
| MOVINGAVERAGE | 返回沿视觉矩阵给定轴计算的移动平均值。 |
| PREVIOUS / NEXT | 读取可视化矩阵中坐标轴上一行/下一行的数,仅用于可视化计算 |
| OFFSET | 按给定偏移量返回同一表格中当前行之前或之后的一行。 |
| ORDERBY | 定义窗口函数各分区中决定排序顺序的列。 |
| PARTITIONBY | 定义用于分割窗口函数relation参数的列。 |
| RANGE | 返回给定坐标轴上相对于当前行的行间隔,WINDOW 函数的快捷方式。 |
| RANK | 返回某一行在给定区间内的排名。 |
| REMOVEFILTERS | 清除指定表或列中的筛选器。 |
| ROWNUMBER | 返回给定区间内某一行的唯一排名。 |
| RUNNINGSUM | 返回沿视觉矩阵给定轴计算的总和。 |
| SELECTEDVALUE | 如果columnName的 Context 已筛选到只有一个不同的值则返回该值,否则返回alternateResult。 |
| WINDOW | 返回位于给定间隔内的多行。 |
表函数
| 函数 | 解释 |
|---|---|
| ADDCOLUMNS | 将计算列添加到给定的表或表表达式。 |
| ADDMISSINGITEMS | 将多个列的组合项添加到表中,如果这些组合项尚不存在。 |
| CROSSJOIN | 返回一个表,其中包含所有表的笛卡尔积。 |
| CURRENTGROUP | 返回 GROUPBY 表达式中表参数的行集。 |
| DATATABLE | 提供声明内联数据值集合的机制。 |
| DETAILROWS | 评估为度量值定义的详细行表达式并返回数据。 |
| DISTINCT column | 返回包含指定列的不同值的单列表。 |
| DISTINCT table | 返回通过从另一个表或表达式中删除重复行得到的表。 |
| EXCEPT | 返回在一个表中存在而另一个表中不存在的行。 |
| FILTERS | 返回直接应用为columnNamefilters 的值的表。 |
| GENERATE / GENERATEALL | 返回一个表,该表是 table1 中每一行与评估 table2 结果的笛卡尔积,且结果是在 table1 的当前 Row Countext 中评估的。 |
| GENERATESERIES | 返回一个包含算术序列值的单列表。 |
| GROUPBY | 与 SUMMARIZE 函数类似,GROUPBY 不会为其添加的任何扩展列执行隐式 CALCULATE。 |
| IGNORE | 通过省略特定表达式来修改 SUMMARIZECOLUMNS,使其不执行 BLANK/NULL 评估。 |
| INTERSECT | 返回两表的行交集,保留重复项。 |
| NATURALINNERJOIN | 对表与另一表进行内连接。 |
| NATURALLEFTOUTERJOIN | 对左表和右表执行连接。 |
| ROLLUP | 通过在 groupBy_columnName 参数定义的列上添加汇总行来修改 SUMMARIZE 的行为。 |
| ROLLUPADDISSUBTOTAL | 通过在 groupBy_columnName 列上添加汇总/小计行来修改 SUMMARIZECOLUMNS 的行为。 |
| ROLLUPISSUBTOTAL | 将 ROLLUPADDISSUBTOTAL 添加的列与 ROLLUP 组配对,位于 ADDMISSINGITEMS 表达式中。 |
| ROLLUPGROUP | 通过在 groupBy_columnName 参数定义的列上添加汇总行来修改 SUMMARIZE 和 SUMMARIZECOLUMNS 的行为。 |
| ROW | 返回一个包含表达式结果的单行表。 |
| SELECTCOLUMNS | 将计算列添加到给定的表或表表达式。 |
| SUBSTITUTEWITHINDEX | 返回表示两个表左半连接的表。 |
| SUMMARIZE | 返回请求的总计的汇总表。 |
| SUMMARIZECOLUMNS | 返回一组分组的汇总表。 |
| Table Constructor | 返回一个包含一列或多列的表。 |
| TOPN | 返回指定表的前 N 行。 |
| TREATAS | 将表表达式的结果应用为对不相关表的列的 filters。 |
| UNION | 创建一个由两个表组成的联合表。 |
| VALUES | 返回一个包含指定表或列的不同值的单列表。 |
文本函数
| 函数 | 解释 |
|---|---|
| COMBINEVALUES | 将两个或多个文本字符串合并成一个文本字符串。 |
| CONCATENATE | 将两个文本字符串合并成一个文本字符串。 |
| CONCATENATEX | 将表达式在表中每行的结果连接起来。 |
| EXACT | 比较两个文本字符串,如果完全相同返回 TRUE,否则返回 FALSE。 |
| FIND | 返回一个文本字符串在另一个文本字符串中的起始位置。 |
| FIXED | 将数字四舍五入到指定的小数位数,并返回结果作为文本。 |
| FORMAT | 根据指定的格式将值转换为文本。 |
| LEFT / RIGHT / MID | 从文本字符串的开始/结尾/指定位置处返回指定数量的字符。 |
| LEN | 返回文本字符串中的字符数。 |
| UPPER / LOWER | 将文本字符串中的所有字母转换为大/小写字母。 |
| REPLACE | 根据指定的字符数,将文本字符串的部分替换为其他文本字符串。 |
| REPT | 将文本重复指定的次数。 |
| SEARCH | 返回在从左到右的方向中,第一个找到特定字符或文本字符串的字符位置。 |
| SUBSTITUTE | 在文本字符串中将现有文本替换为新的文本。 |
| TRIM | 移除文本中的所有空格,保留单词之间的单个空格。 |
| UNICHAR | 返回由数字值引用的 Unicode 字符。 |
| UNICODE | 返回文本字符串第一个字符的数字代码。 |
| VALUE | 将表示数字的文本字符串转换为数字。 |
时间智能函数
| 函数 | 解释 |
|---|---|
|
CLOSINGBALANCEYEAR / CLOSINGBALANCEQUARTER / CLOSINGBALANCEMONTH |
计算当前 Context 中每年/每季度/每月的最后日期的表达式。 |
| DATEADD | 返回一个表格,包含一个日期列,日期根据当前 Context 中的日期按指定的间隔向前或向后移动。 |
| DATESBETWEEN | 返回一个表格,包含一个日期列,开始于指定的起始日期,直到指定的结束日期。 |
| DATESINPERIOD | 返回一个表格,包含一个日期列,开始于指定的起始日期,并持续指定数量和类型的日期间隔。 |
| DATESYTD / DATESQTD / DATESMTD | 返回一个表格,包含当前 Context 中年度/季度/月度至今的日期列。 |
| ENDOFYEAR / ENDOFQUARTER / ENDOFMONTH | 返回当前 Context 中指定日期列的年份/季度/月度的最后日期。 |
| FIRSTDATE / LASTDATE | 返回当前 Context 中指定日期列的第一个/最后一个日期。 |
|
NEXTYEAR /
NEXTQUARTER / NEXTMONTH / NEXTDAY |
返回一个表格,包含基于当前 Context 中日期列中指定日期的下一年/季度/月/天的所有日期。 |
|
OPENINGBALANCEYEAR / OPENINGBALANCEQUARTER / OPENINGBALANCEMONTH |
计算当前 Context 中每年/季度/月的第一日期的表达式。 |
| PARALLELPERIOD | 返回一个表格,包含一个日期列,表示与指定日期列中日期平行的期间,日期可以根据指定的时间间隔向前或向后移动。 |
|
PREVIOUSYEAR /
PREVIOUSQUARTER / PREVIOUSMONTH / PREVIOUSDAY |
返回一个表格,包含基于当前 Context 中日期列中指定日期的上一年/季度/月/天的所有日期。 |
| SAMEPERIODLASTYEAR | 返回一个表格,包含基于指定日期列中日期的前一年相同期间的日期。 |
| STARTOFYEAR / STARTOFQUARTER / STARTOFMONTH | 返回当前 Context 中指定日期列的年份/季度/月份的第一日期。 |
| TOTALYTD / TOTALQTD / TOTALMTD | 计算当前 Context 中的年度/季度/月份至今的表达式的值。 |